OpenAI представила модель CriticGPT, яка шукає помилки у згенерованому ChatGPT коді та відповідях
Дослідники OpenAI представили CriticGPT – нову модель штучного інтелекту, призначену для виявлення та критики помилок у коді, згенерованому ChatGPT, повідомляє Ars Technica. Ця модель спрямована на поліпшення відповідності ШІ-систем людським очікуванням за допомогою навчання з підкріпленням на основі зворотного зв’язку з людиною (RLHF), що підвищує точність вихідних даних великої мовної моделі (LLM).
У своїй дослідницькій роботі “Критики LLM допомагають виявляти помилки LLM” OpenAI пояснює, що CriticGPT служить помічником для людей-тренерів, які переглядають програмний код, згенерований ChatGPT. Побудований на основі сімейства LLM GPT-4, CriticGPT аналізує код і виділяє потенційні помилки, допомагаючи людям-рецензентам виявляти помилки, які в іншому випадку можуть залишитися непоміченими.
Розробка CriticGPT включала навчання моделі на численних вхідних даних, що містили навмисні помилки. Люди-тренери модифікували код, написаний ChatGPT, вносили помилки та надавали зворотний зв’язок так, ніби вони самі виявили ці помилки. Цей процес дозволив моделі навчитися виявляти та критикувати різні типи помилок кодування.
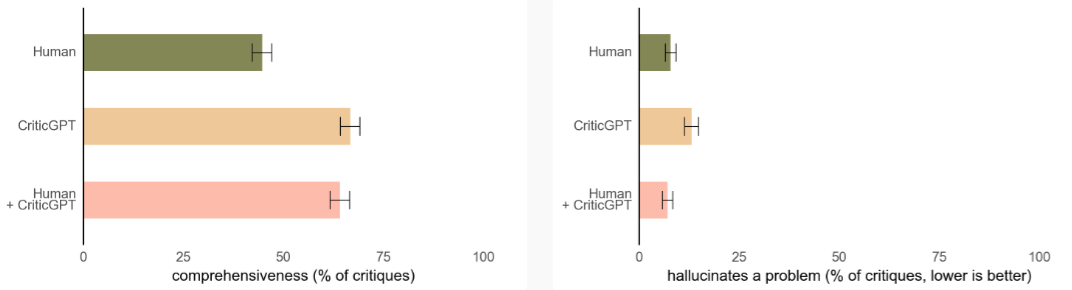
Дослідження показало, що спільна робота команди людей і CriticGPT надавала більш вичерпні критичні зауваження, ніж люди, і знизили частоту галюцинацій ШІ.
Цікаво, що можливості CriticGPT не обмежуються оглядом коду. Модель була протестована на підмножині навчальних даних ChatGPT, які раніше були оцінені людьми, як бездоганні. CriticGPT виявив помилки у 24% цих даних, що пізніше було підтверджено людьми-рецензентами. Це демонструє потенціал моделі для виявлення ледь помітних помилок, які навіть ретельна людська оцінка може пропустити.
Попри багатообіцяючі результати, CriticGPT має обмеження. Її тренували на відносно коротких відповідях ChatGPT, що може не повністю підготувати модель до оцінювання довших і складніших відповідей. Крім того, хоча CriticGPT зменшує кількість галюцинацій ШІ, він не усуває їх повністю, і люди-тренери все ще можуть робити помилки в маркуванні, ґрунтуючись на цих помилкових результатах.
Дослідницька група визнає, що CriticGPT найефективніший у виявленні помилок у певних місцях коду. Однак реальні помилки у результатах ШІ часто можуть бути поширені на кілька частин відповіді, що створює проблему для майбутніх ітерацій моделі.
OpenAI планує інтегрувати моделі, подібні до CriticGPT, у свій конвеєр маркування RLHF, надаючи ШІ-допомогу своїм тренерам. Цей крок спрямований на розробку кращих інструментів для оцінки результатів роботи систем LLM, які може бути важко оцінити людині без додаткової допомоги.